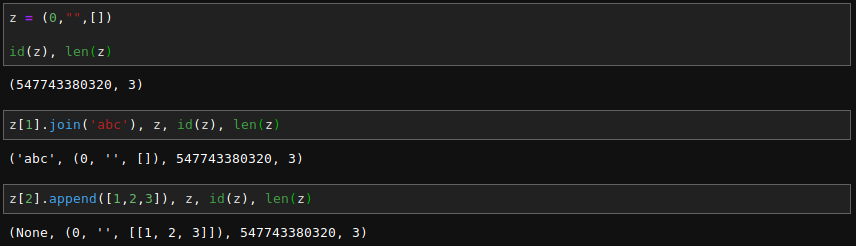
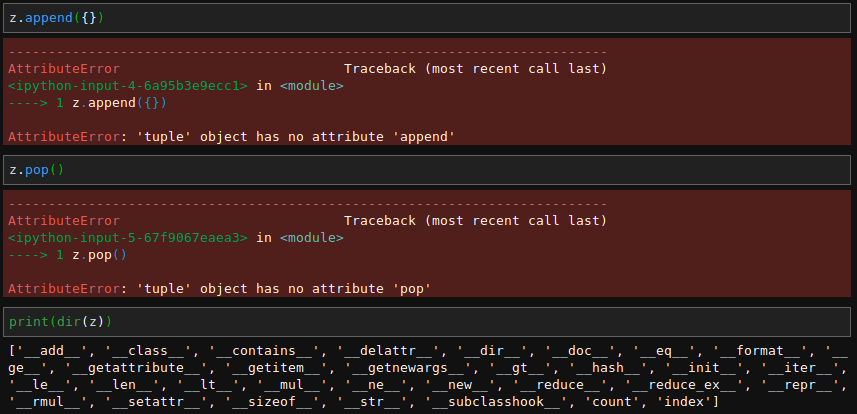
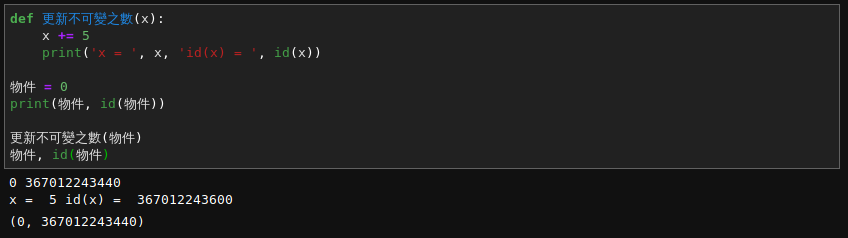
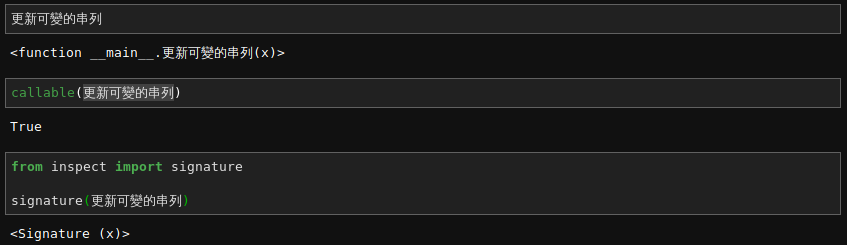
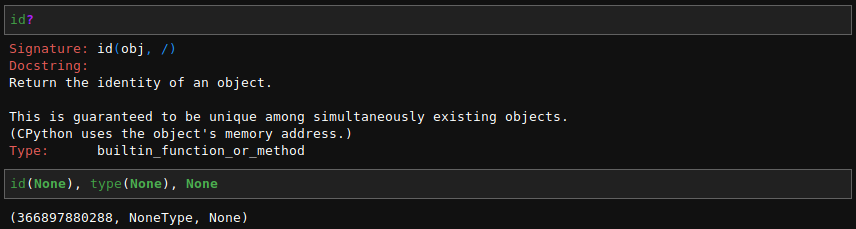
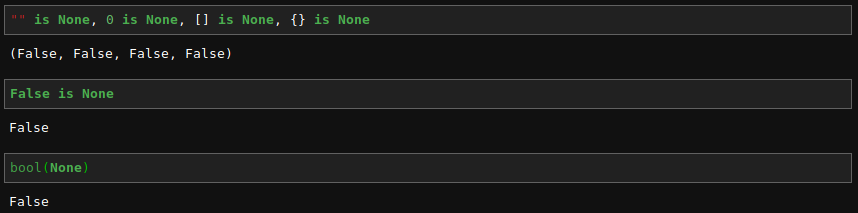
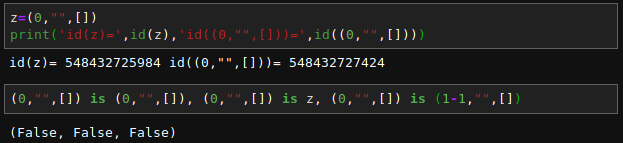
現在讀者已經清楚知道『可變性』 mutability 是由物件『類型』 type 而定,並不是借『身份』 id() 同異區分。大概不會驚訝
 吧!
吧!

事實上, 。
。
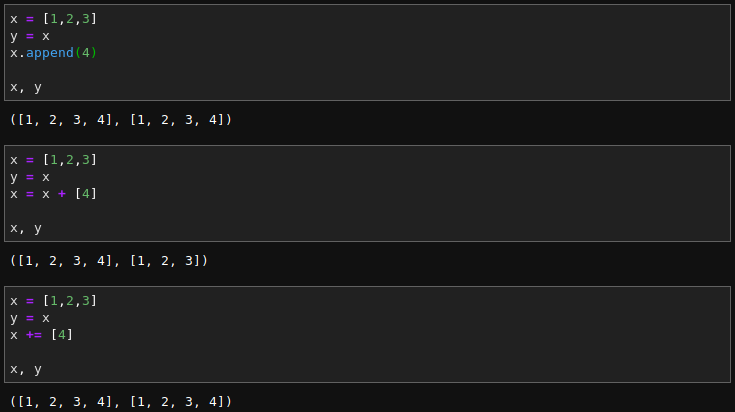
物件『可變性』的重要性在於,用多個『標識符』來存取,當物件異時異地為廣義運算更改時,這些『標識符』當下所指何物呢?
『不可變』物件︰『原物件』 5 保留於 b 。

『可變』物件︰『原物件』y = [1,2,3] 通常跟著 x 變也。
這使得派生『標識符』和『物件』間之關係十分微妙,不好與其他語言比類,所以『賦值陳述』方說『【再】綁定』乎??
7.2. Assignment statements
Assignment statements are used to (re)bind names to values and to modify attributes or items of mutable objects:
如是才能定奪需不需要『【深】拷貝』也!!
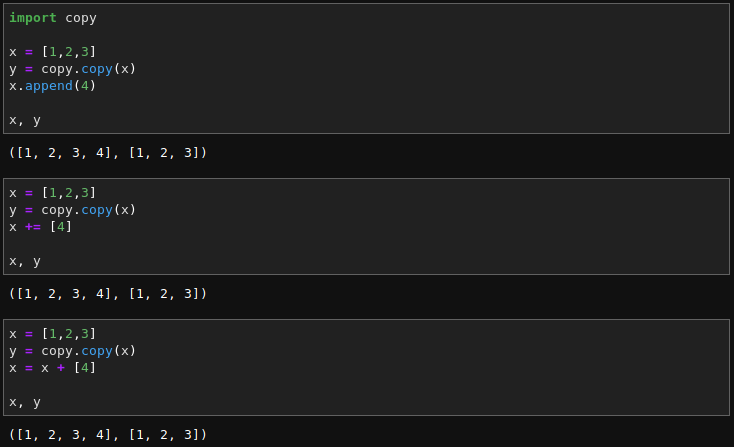
那麼講到物件『賦值』應該很簡單了吧!
讀讀下面文本,然後再次思考上面字句,自己回答耶?
6.10.1. Value comparisons
The operators <, >, ==, >=, <=, and != compare the values of two objects. The objects do not need to have the same type.
Chapter Objects, values and types states that objects have a value (in addition to type and identity). The value of an object is a rather abstract notion in Python: For example, there is no canonical access method for an object’s value. Also, there is no requirement that the value of an object should be constructed in a particular way, e.g. comprised of all its data attributes. Comparison operators implement a particular notion of what the value of an object is. One can think of them as defining the value of an object indirectly, by means of their comparison implementation.
Because all types are (direct or indirect) subtypes of object, they inherit the default comparison behavior from object. Types can customize their comparison behavior by implementing rich comparison methods like __lt__(), described in Basic customization.
The default behavior for equality comparison (== and !=) is based on the identity of the objects. Hence, equality comparison of instances with the same identity results in equality, and equality comparison of instances with different identities results in inequality. A motivation for this default behavior is the desire that all objects should be reflexive (i.e. x is y implies x == y).
A default order comparison (<, >, <=, and >=) is not provided; an attempt raises TypeError. A motivation for this default behavior is the lack of a similar invariant as for equality.
The behavior of the default equality comparison, that instances with different identities are always unequal, may be in contrast to what types will need that have a sensible definition of object value and value-based equality. Such types will need to customize their comparison behavior, and in fact, a number of built-in types have done that.
The following list describes the comparison behavior of the most important built-in types.
-
Numbers of built-in numeric types (Numeric Types — int, float, complex) and of the standard library types
fractions.Fractionanddecimal.Decimalcan be compared within and across their types, with the restriction that complex numbers do not support order comparison. Within the limits of the types involved, they compare mathematically (algorithmically) correct without loss of precision.The not-a-number values
float('NaN')andDecimal('NaN')are special. They are identical to themselves (x is xis true) but are not equal to themselves (x == xis false). Additionally, comparing any number to a not-a-number value will returnFalse. For example, both3 < float('NaN')andfloat('NaN') < 3will returnFalse. -
Binary sequences (instances of
bytesorbytearray) can be compared within and across their types. They compare lexicographically using the numeric values of their elements. -
Strings (instances of
str) compare lexicographically using the numerical Unicode code points (the result of the built-in functionord()) of their characters. [3]Strings and binary sequences cannot be directly compared.
-
Sequences (instances of
tuple,list, orrange) can be compared only within each of their types, with the restriction that ranges do not support order comparison. Equality comparison across these types results in unequality, and ordering comparison across these types raisesTypeError.Sequences compare lexicographically using comparison of corresponding elements, whereby reflexivity of the elements is enforced.
In enforcing reflexivity of elements, the comparison of collections assumes that for a collection element
x,x == xis always true. Based on that assumption, element identity is compared first, and element comparison is performed only for distinct elements. This approach yields the same result as a strict element comparison would, if the compared elements are reflexive. For non-reflexive elements, the result is different than for strict element comparison, and may be surprising: The non-reflexive not-a-number values for example result in the following comparison behavior when used in a list:>>> nan = float('NaN') >>> nan is nan True >>> nan == nan False <-- the defined non-reflexive behavior of NaN >>> [nan] == [nan] True <-- list enforces reflexivity and tests identity firstLexicographical comparison between built-in collections works as follows:
- For two collections to compare equal, they must be of the same type, have the same length, and each pair of corresponding elements must compare equal (for example,
[1,2] == (1,2)is false because the type is not the same). - Collections that support order comparison are ordered the same as their first unequal elements (for example,
[1,2,x] <= [1,2,y]has the same value asx <= y). If a corresponding element does not exist, the shorter collection is ordered first (for example,[1,2] < [1,2,3]is true).
- For two collections to compare equal, they must be of the same type, have the same length, and each pair of corresponding elements must compare equal (for example,
-
Mappings (instances of
dict) compare equal if and only if they have equal (key, value) pairs. Equality comparison of the keys and values enforces reflexivity.Order comparisons (
<,>,<=, and>=) raiseTypeError. -
Sets (instances of
setorfrozenset) can be compared within and across their types.They define order comparison operators to mean subset and superset tests. Those relations do not define total orderings (for example, the two sets
{1,2}and{2,3}are not equal, nor subsets of one another, nor supersets of one another). Accordingly, sets are not appropriate arguments for functions which depend on total ordering (for example,min(),max(), andsorted()produce undefined results given a list of sets as inputs).Comparison of sets enforces reflexivity of its elements.
-
Most other built-in types have no comparison methods implemented, so they inherit the default comparison behavior.
User-defined classes that customize their comparison behavior should follow some consistency rules, if possible:
-
Equality comparison should be reflexive. In other words, identical objects should compare equal:
x is yimpliesx == y -
Comparison should be symmetric. In other words, the following expressions should have the same result:
x == yandy == xx != yandy != xx < yandy > xx <= yandy >= x -
Comparison should be transitive. The following (non-exhaustive) examples illustrate that:
x > y and y > zimpliesx > zx < y and y <= zimpliesx < z -
Inverse comparison should result in the boolean negation. In other words, the following expressions should have the same result:
x == yandnot x != yx < yandnot x >= y(for total ordering)x > yandnot x <= y(for total ordering)The last two expressions apply to totally ordered collections (e.g. to sequences, but not to sets or mappings). See also the
total_ordering()decorator. -
The
hash()result should be consistent with equality. Objects that are equal should either have the same hash value, or be marked as unhashable.
Python does not enforce these consistency rules. In fact, the not-a-number values are an example for not following these rules.