Michael Nielsen 先生此段文字是本章的重點,他先從
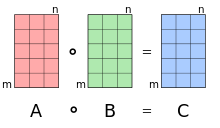
The backpropagation algorithm is based on common linear algebraic operations – things like vector addition, multiplying a vector by a matrix, and so on. But one of the operations is a little less commonly used. In particular, suppose s and t are two vectors of the same dimension. Then we use  to denote the elementwise product of the two vectors. Thus the components of are just
to denote the elementwise product of the two vectors. Thus the components of are just  . As an example,
. As an example,
![\left[\begin{array}{c} 1 \\ 2 \end{array}\right] \odot \left[\begin{array}{c} 3 \\ 4\end{array} \right] = \left[ \begin{array}{c} 1 * 3 \\ 2 * 4 \end{array} \right] = \left[ \begin{array}{c} 3 \\ 8 \end{array} \right]. \ \ \ \ (28)](http://www.freesandal.org/wp-content/ql-cache/quicklatex.com-9106bf28ddf8945e7d7f184acec50495_l3.png "Rendered by QuickLaTeX.com")
This kind of elementwise multiplication is sometimes called the Hadamard product or Schur product. We’ll refer to it as the Hadamard product. Good matrix libraries usually provide fast implementations of the Hadamard product, and that comes in handy when implementing backpropagation.
───
講起,是希望藉著『記號法』,方便讀者理解『反向傳播算法』的內容。這個稱作 Hadamard product 之『對應元素乘法』
Hadamard product (matrices)
In mathematics, the Hadamard product (also known as the Schur product[1] or the entrywise product[2]) is a binary operation that takes two matrices of the same dimensions, and produces another matrix where each element ij is the product of elements ij of the original two matrices. It should not be confused with the more common matrix product. It is attributed to, and named after, either French mathematician Jacques Hadamard, or German mathematician Issai Schur.
The Hadamard product is associative and distributive, and unlike the matrix product it is also commutative.
The Hadamard product operates on identically-shaped matrices and produces a third matrix of the same dimensions.
Definition
For two matrices, 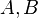 , of the same dimension,
, of the same dimension,  the Hadamard product,
the Hadamard product,  , is a matrix, of the same dimension as the operands, with elements given by
, is a matrix, of the same dimension as the operands, with elements given by
 .
.
For matrices of different dimensions ( and  , where
, where  or
or  or both) the Hadamard product is undefined.
or both) the Hadamard product is undefined.
Example
For example, the Hadamard product for a 3×3 matrix A with a 3×3 matrix B is:

───
明晰易解,大概無需畫蛇添足的吧!然而接下來的『妖怪說』︰
The four fundamental equations behind backpropagation
Backpropagation is about understanding how changing the weights and biases in a network changes the cost function. Ultimately, this means computing the partial derivatives  and
and  . But to compute those, we first introduce an intermediate quantity,
. But to compute those, we first introduce an intermediate quantity,  , which we call the error in the
, which we call the error in the  neuron in the
neuron in the  layer. Backpropagation will give us a procedure to compute the error , and then will relate to and .
layer. Backpropagation will give us a procedure to compute the error , and then will relate to and .
To understand how the error is defined, imagine there is a demon in our neural network:
 neuron in layer
neuron in layer  . As the input to the neuron comes in, the demon messes with the neuron’s operation. It adds a little change
. As the input to the neuron comes in, the demon messes with the neuron’s operation. It adds a little change  to the neuron’s weighted input, so that instead of outputting
to the neuron’s weighted input, so that instead of outputting  , the neuron instead outputs
, the neuron instead outputs  . This change propagates through later layers in the network, finally causing the overall cost to change by an amount
. This change propagates through later layers in the network, finally causing the overall cost to change by an amount  .
.
Now, this demon is a good demon, and is trying to help you improve the cost, i.e., they’re trying to find a which makes the cost smaller. Suppose  has a large value (either positive or negative). Then the demon can lower the cost quite a bit by choosing to have the opposite sign to . By contrast, if is close to zero, then the demon can’t improve the cost much at all by perturbing the weighted input
has a large value (either positive or negative). Then the demon can lower the cost quite a bit by choosing to have the opposite sign to . By contrast, if is close to zero, then the demon can’t improve the cost much at all by perturbing the weighted input  . So far as the demon can tell, the neuron is already pretty near optimal*
. So far as the demon can tell, the neuron is already pretty near optimal*
*This is only the case for small changes , of course. We’ll assume that the demon is constrained to make such small changes..
And so there’s a heuristic sense in which is a measure of the error in the neuron.
Motivated by this story, we define the error of neuron  in layer by
in layer by

As per our usual conventions, we use  to denote the vector of errors associated with layer . Backpropagation will give us a way of computing for every layer, and then relating those errors to the quantities of real interest, and .
to denote the vector of errors associated with layer . Backpropagation will give us a way of computing for every layer, and then relating those errors to the quantities of real interest, and .
You might wonder why the demon is changing the weighted input . Surely it’d be more natural to imagine the demon changing the output activation  , with the result that we’d be using
, with the result that we’d be using  as our measure of error. In fact, if you do this things work out quite similarly to the discussion below. But it turns out to make the presentation of backpropagation a little more algebraically complicated. So we’ll stick with
as our measure of error. In fact, if you do this things work out quite similarly to the discussion below. But it turns out to make the presentation of backpropagation a little more algebraically complicated. So we’ll stick with  as our measure of error*
as our measure of error*
*In classification problems like MNIST the term “error” is sometimes used to mean the classification failure rate. E.g., if the neural net correctly classifies 96.0 percent of the digits, then the error is 4.0 percent. Obviously, this has quite a different meaning from our  vectors. In practice, you shouldn’t have trouble telling which meaning is intended in any given usage..
vectors. In practice, you shouldn’t have trouble telling which meaning is intended in any given usage..
───
確須仔細斟詳,方可確實明白,達成為我所用之目的。或因 Michael Nielsen 先生不能假設讀者知道『矩陣』、『向量』 以及『無窮小』之『萊布尼茲記號法』︰
Leibniz’s notation
In calculus, Leibniz’s notation, named in honor of the 17th-century German philosopher and mathematician Gottfried Wilhelm Leibniz, uses the symbols dx and dy to represent infinitely small (or infinitesimal) increments of x and y, respectively, just as Δx and Δy represent finite increments of x and y, respectively.[1]
Consider y as a function of a variable x, or y = f(x). If this is the case, then the derivative of y with respect to x, which later came to be viewed as the limit
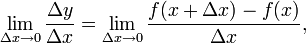
was, according to Leibniz, the quotient of an infinitesimal increment of y by an infinitesimal increment of x, or

where the right hand side is Joseph-Louis Lagrange’s notation for the derivative of f at x. From the point of view of modern infinitesimal theory, Δx is an infinitesimal x-increment, Δy is the corresponding y-increment, and the derivative is the standard part of the infinitesimal ratio:
 .
.
Then one sets 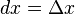 ,
,  , so that by definition,
, so that by definition,  is the ratio of dy by dx.
is the ratio of dy by dx.
Similarly, although mathematicians sometimes now view an integral

as a limit

where Δx is an interval containing xi, Leibniz viewed it as the sum (the integral sign denoting summation) of infinitely many infinitesimal quantities f(x) dx. From the modern viewpoint, it is more correct to view the integral as the standard part of such an infinite sum.

Gottfried Wilhelm von Leibniz (1646 – 1716), German philosopher, mathematician, and namesake of this widely used mathematical notation in calculus.
───
於是方用迂迴的方式來說。如果回顧相干函式關係︰




也許會發現之所以選擇  自然而然順理成章。若是通熟『鏈式法則』
自然而然順理成章。若是通熟『鏈式法則』
Chain rule
In calculus, the chain rule is a formula for computing the derivative of the composition of two or more functions. That is, if f and g are functions, then the chain rule expresses the derivative of their composition f ∘ g (the function which maps x to f(g(x)) in terms of the derivatives of f and g and the product of functions as follows:

This can be written more explicitly in terms of the variable. Let F = f ∘ g, or equivalently, F(x) = f(g(x)) for all x. Then one can also write

The chain rule may be written, in Leibniz’s notation, in the following way. We consider z to be a function of the variable y, which is itself a function of x (y and z are therefore dependent variables), and so, z becomes a function of x as well:

In integration, the counterpart to the chain rule is the substitution rule.
Proof via infinitesimals
If  and
and  then choosing infinitesimal
then choosing infinitesimal  we compute the corresponding
we compute the corresponding 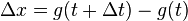 and then the corresponding
and then the corresponding  , so that
, so that
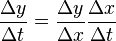
and applying the standard part we obtain

which is the chain rule.
───
該文本之內容會是天經地義無可疑議矣??!!由於『微積分』是閱讀科技著作和文獻之『必修課』與『先修課』,它的深入理解以及直覺掌握,將有莫大價值,故而作者曾假《觀水》一文中京房之『上飛下飛』十六變之法,寫了
《【Sonic π】電路學之補充《四》無窮小算術‧…》一系列文本,期望能助益於萬一也!!??
最後補以『觀察點』之選擇往往會造成不同的『難易度』!!!

具體數學:計算機科學之基石
An ant starts to crawl along a taut rubber rope 1 km long at a speed of 1 cm per second (relative to the rubber it is crawling on). At the same time, the rope starts to stretch uniformly by 1 km per second, so that after 1 second it is 2 km long, after 2 seconds it is 3 km long, etc. Will the ant ever reach the end of the rope?



在『具體數學』這本書中提到了另一個『違反直覺』的例子 ── 橡膠繩上的螞蟻 ──,一隻螞蟻以每秒鐘一公分的速度,在一根長一公里拉緊了的橡膠繩上爬行【螞蟻的爬行速度相對橡膠繩】,就在螞蟻爬行的同時,橡膠繩也以每秒一公里的速度伸長,也就是說一秒後,它有兩公里長,兩秒後有三公里長等等。試問螞蟻果真到的了繩子之另一端的嗎?
假設  時刻時,螞蟻在
時刻時,螞蟻在  的『位置』,以
的『位置』,以  的速度朝另一端爬行,同時橡膠繩用
的速度朝另一端爬行,同時橡膠繩用  的速度同向均勻伸長,因此橡膠繩上的某點
的速度同向均勻伸長,因此橡膠繩上的某點  的伸長速度將是
的伸長速度將是  ,此處
,此處  就是橡膠繩的『原長』,由於起點是『固定』不動的,因此繩上各點的速度與『端點的速度』
就是橡膠繩的『原長』,由於起點是『固定』不動的,因此繩上各點的速度與『端點的速度』  成比例,於是對於一個靜止的觀察者而言,螞蟻的速度將是
成比例,於是對於一個靜止的觀察者而言,螞蟻的速度將是

。 如果我們設想要是橡膠繩並不與時伸展,那麼這隻螞蟻是一定到的了彼端,假使一個相對於繩子靜止的觀察者將看到什麼現象的呢?或許他將用  來描述這隻螞蟻的行進的吧! 它從
來描述這隻螞蟻的行進的吧! 它從  開始爬行,它將會在
開始爬行,它將會在  時刻到達了另一端。由於
時刻到達了另一端。由於
![\frac{d\Phi}{dt} = \frac{d}{dt} \left[ {(c + v t)}^{-1} \cdot x(t) \right]](http://www.freesandal.org/wp-content/ql-cache/quicklatex.com-5a2831e5b19dedbee2a7ebda593beced_l3.png "Rendered by QuickLaTeX.com")

![= {(c + v t)}^{-1} \cdot \left[ \alpha + {(c + v t)}^{-1} \cdot v x(t) \right] - {(c + v t)}^{-2} \cdot v x(t)](http://www.freesandal.org/wp-content/ql-cache/quicklatex.com-869ce2c5de287cc64b7881ea8fcb3716_l3.png "Rendered by QuickLaTeX.com")
 ,因此我們就可以得到
,因此我們就可以得到

此 處  積分常數。從
積分常數。從  ,可以得到
,可以得到  ,所以
,所以  。再從
。再從  ,就得到了
,就得到了  。
。
假使將  代入後,求得
代入後,求得  ,這隻小螞蟻果真到的了彼端,雖然它得經過千千萬萬個三千大劫的吧!!
,這隻小螞蟻果真到的了彼端,雖然它得經過千千萬萬個三千大劫的吧!!
那麼為什麼 ︰某點 的伸長速度會是 的呢?假使考慮一根『有刻度』  的尺,它的一端固定,另一端向外延伸,這樣每個『刻度點』也都相對的向外伸長
的尺,它的一端固定,另一端向外延伸,這樣每個『刻度點』也都相對的向外伸長  ,於是『固定端』
,於是『固定端』  ,『第一個刻度』在
,『第一個刻度』在  的位置,『第二個刻度』在
的位置,『第二個刻度』在  的位置,這樣『第
的位置,這樣『第  個刻度』將在
個刻度』將在  的位置。假設『橡膠繩』的『彈性』是『均勻』的,這樣所有的
的位置。假設『橡膠繩』的『彈性』是『均勻』的,這樣所有的  都相等,因此
都相等,因此  ,如此當『另一端』用『定速』 移動時,此時
,如此當『另一端』用『定速』 移動時,此時  ,於是『第 個刻度』就用
,於是『第 個刻度』就用  的速度在移動的啊!
的速度在移動的啊!
過去有人曾經想像過一種情況︰如果說宇宙中的一切,在夜間會突然的『變大』或者『縮小』,那麼我們能夠『發現』的嗎?假使從『量測』的觀點來看,如果度量用的『尺』  隨著時間改變,『被度量事物』的『大小』
隨著時間改變,『被度量事物』的『大小』  也『協同』的跟隨著變化
也『協同』的跟隨著變化  ,這樣在那個『宇宙』 裡面
,這樣在那個『宇宙』 裡面  ,也就是講『測量』沒有辦法『知道』到底『有沒有』發生過這件事的啊!!然而這卻更進一步引發了『自然定律』到底是否會在『度量單位』的改變下,而有所不同的呢??
,也就是講『測量』沒有辦法『知道』到底『有沒有』發生過這件事的啊!!然而這卻更進一步引發了『自然定律』到底是否會在『度量單位』的改變下,而有所不同的呢??
── 摘自《【Sonic π】電路學之補充《四》無窮小算術‧中下中‧中》