雖說我們不能從維基百科詞條
人工神經網絡
人工神經網絡(artificial neural network,縮寫ANN),簡稱神經網絡(neural network,縮寫NN)或類神經網絡,是一種模仿生物神經網絡(動物的中樞神經系統,特別是大腦)的結構和功能的數學模型或計算模型。神經網絡由大量的人工神經元聯結進行計算。大多數情況下人工神經網絡能在外界信息的基礎上改變內部結構,是一種自適應系統。現代神經網絡是一種非線性統計性數據建模工具,常用來對輸入和輸出間複雜的關係進行建模,或用來探索數據的模式。
神經網絡是一種運算模型[1],由大量的節點(或稱「神經元」, 或「單元」)和之間相互聯接構成。每個節點代表一種特定的輸出函數,稱為激勵函數(activation function)。每兩個節點間的連接都代表一個對於通過該連接信號的加權值,稱之為權重(weight),這相當於人工神經網路的記憶。網絡的輸出則 依網絡的連接方式,權重值和激勵函數的不同而不同。而網絡自身通常都是對自然界某種算法或者函數的逼近,也可能是對一種邏輯策略的表達。
例如,用於手寫識別的一個神經網絡是被可由一個輸入圖像的像素被激活的一組輸入神經元所定義的。在通過函數(由網絡的設計者確定)進行加權和變換之後,這些神經元被激活然後被傳遞到其他神經元。重複這一過程,直到最後一個輸出神經元被激活。這樣決定了被讀取的字。
它的構築理念是受到生物(人或其他動物)神經網絡功能的運作啟發而產生的。人工神經網絡通常是通過一個基於數學統計學類型的學習方法 (Learning Method)得以優化,所以人工神經網絡也是數學統計學方法的一種實際應用,通過統計學的標準數學方法我們能夠得到大量的可以用函數來表達的局部結構空 間,另一方面在人工智慧學的人工感知領域,我們通過數學統計學的應用可以來做人工感知方面的決定問題(也就是說通過統計學的方法,人工神經網絡能夠類似人 一樣具有簡單的決定能力和簡單的判斷能力),這種方法比起正式的邏輯學推理演算更具有優勢。
───
真實知道『神經網絡』到底是什麼 □ ○ ?彷彿不外乎熟悉『名詞』而已!
但是《老子》為什麼卻又講
道可道,非常道。名可名,非常名。無名天地之始,有名萬物之母 。故常無欲,以觀其妙;常有欲,以觀其徼。此兩者同出而異名,同謂之玄,玄之又玄,眾妙之門。
因此所謂
深度學習
深度學習(英語:deep learning)是機器學習的一個分支,它基於試圖使用包含複雜結構或由多重非線性變換構成的多個處理層對資料進行高層抽象的一系列演算法。[1][2][3][4][5]
深度學習是機器學習中表征學習方法的一類。一個觀測值(例如一幅圖像)可以使用多種方式來表示,如每個像素強度值的向量,或者更抽象地表示成一系列邊、特定形狀的區域等。而使用某些特定的表示方法更加容易地從例項中學習任務(例如,人臉識別或面部表情識別[6])。深度學習的好處之一是將用非監督式或半監督式的特徵學習和分層特徵提取的高效演算法來替代手工取得特徵。[7]
表征學習的目標是尋求更好的表示方法並建立更好的模型來從大規模未標記資料中學習這些表示方法。一些表達方式的靈感來自於神經科學的進步,並鬆散地建立在神經系統中的資訊處理和通信模式的理解基礎上,如神經編碼,試圖定義刺激和神經元的反應之間的關係以及大腦中的神經元的電活動之間的關係。[8]
至今已有多種深度學習框架,如深度神經網路、卷積神經網路和深度信念網路和遞迴神經網路已被應用於電腦視覺、語音識別、自然語言處理、音訊識別與生物資訊學等領域並取得了極好的效果。
另外,深度學習已成為一個時髦術語,或者說是神經網路的品牌重塑。[9][10]
───
亦藏於『眾妙之門』之玄境耶!?
若問『廣泛學習』可否得到利益?
Artificial neural network
In machine learning and cognitive science, artificial neural networks (ANNs) are a family of models inspired by biological neural networks (the central nervous systems of animals, in particular the brain) and are used to estimate or approximate functions that can depend on a large number of inputs and are generally unknown. Artificial neural networks are generally presented as systems of interconnected “neurons” which exchange messages between each other. The connections have numeric weights that can be tuned based on experience, making neural nets adaptive to inputs and capable of learning.
For example, a neural network for handwriting recognition is defined by a set of input neurons which may be activated by the pixels of an input image. After being weighted and transformed by a function (determined by the network’s designer), the activations of these neurons are then passed on to other neurons. This process is repeated until finally, an output neuron is activated. This determines which character was read.
Like other machine learning methods – systems that learn from data – neural networks have been used to solve a wide variety of tasks that are hard to solve using ordinary rule-based programming, including computer vision and speech recognition.
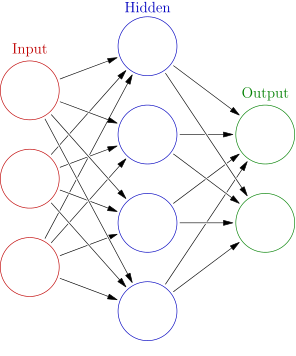
An artificial neural network is an interconnected group of nodes, akin to the vast network of neurons in a brain. Here, each circular node represents an artificial neuron and an arrow represents a connection from the output of one neuron to the input of another.
……
探索歷史
History
Warren McCulloch and Walter Pitts[2] (1943) created a computational model for neural networks based on mathematics and algorithms called threshold logic. This model paved the way for neural network research to split into two distinct approaches. One approach focused on biological processes in the brain and the other focused on the application of neural networks to artificial intelligence.
Hebbian learning
In the late 1940s psychologist Donald Hebb[3] created a hypothesis of learning based on the mechanism of neural plasticity that is now known as Hebbian learning. Hebbian learning is considered to be a ‘typical’ unsupervised learning rule and its later variants were early models for long term potentiation. Researchers started applying these ideas to computational models in 1948 with Turing’s B-type machines.
Farley and Wesley A. Clark[4] (1954) first used computational machines, then called “calculators,” to simulate a Hebbian network at MIT. Other neural network computational machines were created by Rochester, Holland, Habit, and Duda[5] (1956).
Frank Rosenblatt[6] (1958) created the perceptron, an algorithm for pattern recognition based on a two-layer computer learning network using simple addition and subtraction. With mathematical notation, Rosenblatt also described circuitry not in the basic perceptron, such as the exclusive-or circuit, a circuit which could not be processed by neural networks until after the backpropagation algorithm was created by Paul Werbos[7] (1975).
Neural network research stagnated after the publication of machine learning research by Marvin Minsky and Seymour Papert[8] (1969), who discovered two key issues with the computational machines that processed neural networks. The first was that basic perceptrons were incapable of processing the exclusive-or circuit. The second significant issue was that computers didn’t have enough processing power to effectively handle the long run time required by large neural networks. Neural network research slowed until computers achieved greater processing power.
Backpropagation and Resurgence
A key advance that came later was the backpropagation algorithm which effectively solved the exclusive-or problem, and more generally the problem of quickly training multi-layer neural networks (Werbos 1975).[7]
In the mid-1980s, parallel distributed processing became popular under the name connectionism. The textbook by David E. Rumelhart and James McClelland[9] (1986) provided a full exposition of the use of connectionism in computers to simulate neural processes.
Neural networks, as used in artificial intelligence, have traditionally been viewed as simplified models of neural processing in the brain, even though the relation between this model and the biological architecture of the brain is debated; it’s not clear to what degree artificial neural networks mirror brain function.[10]
Support vector machines and other, much simpler methods such as linear classifiers gradually overtook neural networks in machine learning popularity. But the advent of deep learning in the late 2000s sparked renewed interest in neural nets.
Improvements since 2006
Computational devices have been created in CMOS, for both biophysical simulation and neuromorphic computing. More recent efforts show promise for creating nanodevices[11] for very large scale principal components analyses and convolution. If successful, these efforts could usher in a new era of neural computing[12] that is a step beyond digital computing, because it depends on learning rather than programming and because it is fundamentally analog rather than digital even though the first instantiations may in fact be with CMOS digital devices.
Between 2009 and 2012, the recurrent neural networks and deep feedforward neural networks developed in the research group of Jürgen Schmidhuber at the Swiss AI Lab IDSIA have won eight international competitions in pattern recognition and machine learning.[13][14] For example, the bi-directional and multi-dimensional long short term memory (LSTM)[15][16][17][18] of Alex Graves et al. won three competitions in connected handwriting recognition at the 2009 International Conference on Document Analysis and Recognition (ICDAR), without any prior knowledge about the three different languages to be learned.
Fast GPU-based implementations of this approach by Dan Ciresan and colleagues at IDSIA have won several pattern recognition contests, including the IJCNN 2011 Traffic Sign Recognition Competition,[19][20] the ISBI 2012 Segmentation of Neuronal Structures in Electron Microscopy Stacks challenge,[21] and others. Their neural networks also were the first artificial pattern recognizers to achieve human-competitive or even superhuman performance[22] on important benchmarks such as traffic sign recognition (IJCNN 2012), or the MNIST handwritten digits problem of Yann LeCun at NYU.
Deep, highly nonlinear neural architectures similar to the 1980 neocognitron by Kunihiko Fukushima[23] and the “standard architecture of vision”,[24] inspired by the simple and complex cells identified by David H. Hubel and Torsten Wiesel in the primary visual cortex, can also be pre-trained by unsupervised methods[25][26] of Geoff Hinton‘s lab at University of Toronto.[27][28] A team from this lab won a 2012 contest sponsored by Merck to design software to help find molecules that might lead to new drugs.[29]
───
能否有所啟發!誠大哉問的也?!
故而只因『小巧完整』,宣說 Michael Nielsen 的
Neural Networks and Deep Learning 文本︰
Neural networks are one of the most beautiful programming paradigms ever invented. In the conventional approach to programming, we tell the computer what to do, breaking big problems up into many small, precisely defined tasks that the computer can easily perform. By contrast, in a neural network we don’t tell the computer how to solve our problem. Instead, it learns from observational data, figuring out its own solution to the problem at hand.
Automatically learning from data sounds promising. However, until 2006 we didn’t know how to train neural networks to surpass more traditional approaches, except for a few specialized problems. What changed in 2006 was the discovery of techniques for learning in so-called deep neural networks. These techniques are now known as deep learning. They’ve been developed further, and today deep neural networks and deep learning achieve outstanding performance on many important problems in computer vision, speech recognition, and natural language processing. They’re being deployed on a large scale by companies such as Google, Microsoft, and Facebook.
The purpose of this book is to help you master the core concepts of neural networks, including modern techniques for deep learning. After working through the book you will have written code that uses neural networks and deep learning to solve complex pattern recognition problems. And you will have a foundation to use neural networks and deep learning to attack problems of your own devising.
……
It’s rare for a book to aim to be both principle-oriented and hands-on. But I believe you’ll learn best if we build out the fundamental ideas of neural networks. We’ll develop living code, not just abstract theory, code which you can explore and extend. This way you’ll understand the fundamentals, both in theory and practice, and be well set to add further to your knowledge.
且留大部頭之『未出版』大作
Deep Learning
An MIT Press book in preparation
Ian Goodfellow, Yoshua Bengio and Aaron Courville
The Deep Learning textbook is a resource intended to help students and practitioners enter the field of machine learning in general and deep learning in particular. The book will be available for sale soon, and will remain available online for free.
Citing the book in preparation
To cite this book in preparation, please use this bibtex entry:
@unpublished{Goodfellow-et-al-2016-Book,
title={Deep Learning},
author={Ian Goodfellow, Yoshua Bengio, and Aaron Courville},
note={Book in preparation for MIT Press},
url={http://www.deeplearningbook.org},
year={2016}
}
───
于有興趣者自享的哩??!!