如果蟲鳴鳥叫是天生本能,那麼人類講話也是天賦自然。但是萬物發聲之『物理模型』卻很難建造。因此
Gnuspeech is an extensible text-to-speech computer software package that produces artificial speech output based on real-time articulatory speech synthesis by rules. That is, it converts text strings into phonetic descriptions, aided by a pronouncing dictionary, letter-to-sound rules, and rhythm and intonation models; transforms the phonetic descriptions into parameters for a low-level articulatory speech synthesizer; uses these to drive an articulatory model of the human vocal tract producing an output suitable for the normal sound output devices used by various computer operating systems; and does this at the same or faster rate than the speech is spoken for adult speech.
Design
The synthesizer is a tube resonance, or waveguide, model that models the behavior of the real vocal tract directly, and reasonably accurately, unlike formant synthesizers that indirectly model the speech spectrum.[1] The control problem is solved by using René Carré’s Distinctive Region Model[2] which relates changes in the radii of eight longitudinal divisions of the vocal tract to corresponding changes in the three frequency formants in the speech spectrum that convey much of the information of speech. The regions are, in turn, based on work by the Stockholm Speech Technology Laboratory[3] of the Royal Institute of Technology (KTH) on “formant sensitivity analysis” – that is, how formant frequencies are affected by small changes in the radius of the vocal tract at various places along its length.[4]
或許代表一種『聲音合成』的未來。其中『聲道』
The vocal tract is the cavity in human beings and in animals where sound that is produced at the sound source (larynx in mammals; syrinx in birds) is filtered.
In birds it consists of the trachea, the syrinx, the oral cavity, the upper part of the esophagus, and the beak. In mammals it consists of the laryngeal cavity, the pharynx, the oral cavity, and the nasal cavity.
The estimated average length of the vocal tract in adult male humans is 16.9 cm and 14.1 cm in adult females.[1]
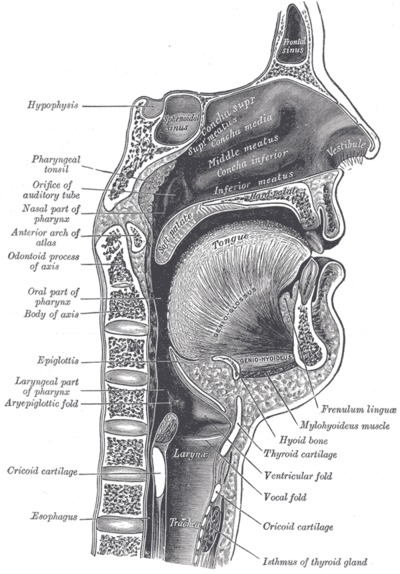
Sagittal section of human vocal tract
模型就是型塑萬物音聲特色的基礎。欣聞
[Posted October 21, 2015 by n8willis]
| From: |
|
David Hill <drh-AT-firethorne.com> |
| To: |
|
Gnu Announce <info-gnu-AT-gnu.org> |
| Subject: |
|
First release of gnuspeech project software |
| Date: |
|
Mon, 19 Oct 2015 18:41:22 -0700 |
| Message-ID: |
|
<AD48546B-E89C-4F7C-A2C5-D45D5C3C46A3@firethorne.com> |
| Archive-link: |
|
Article, Thread |
gnuspeech-0.9 and gnuspeechsa-0.1.5 first official release
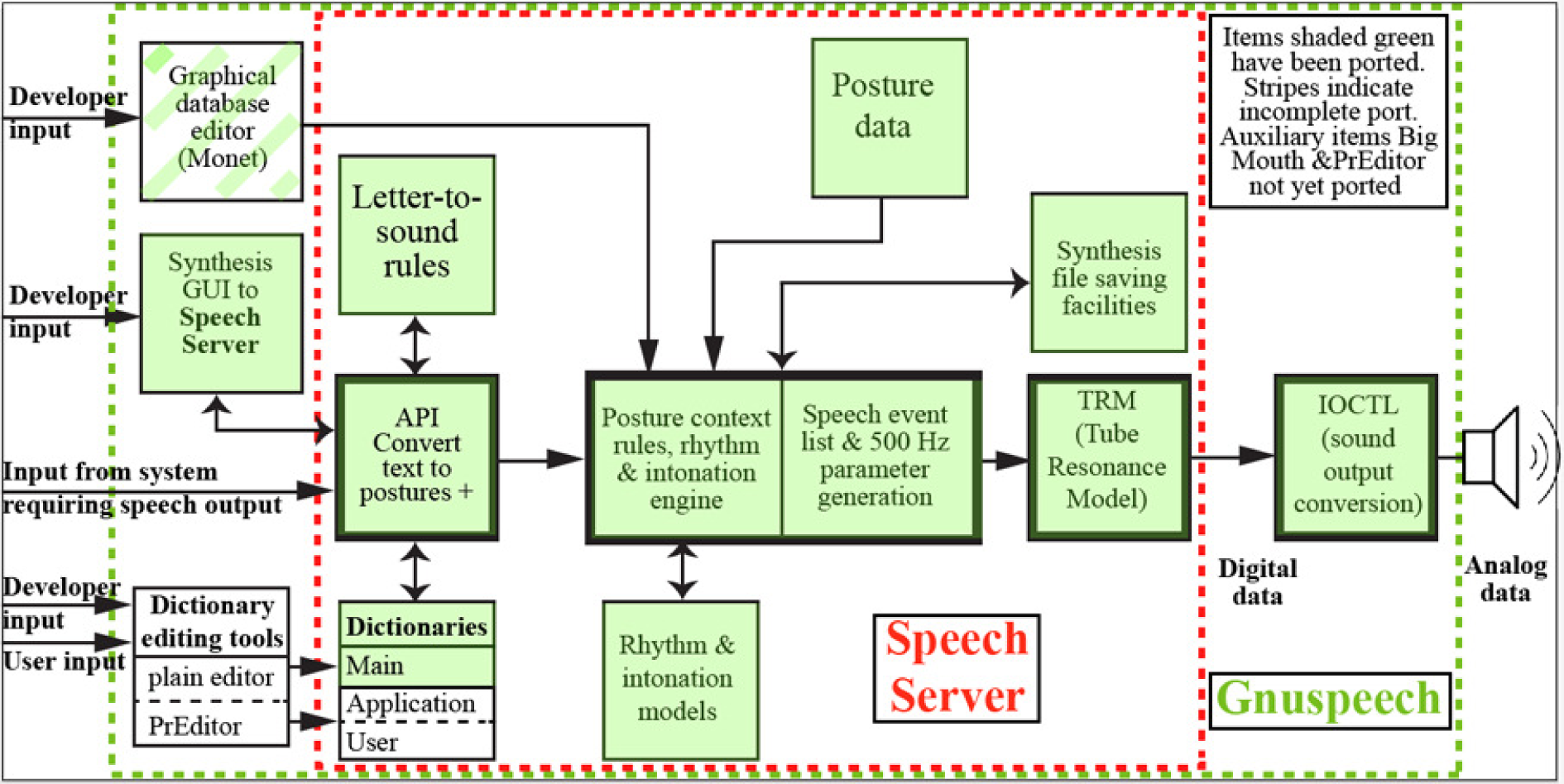
Gnuspeech is new approach to synthetic speech as well as a speech research tool. It comprises a true articulatory model of the vocal tract, databases and rules for parameter composition, a 70,000 word plus pronouncing dictionary, a letter-to-sound fall-back module, and models of English rhythm and intonation, all based on extensive research that sets a new standard for synthetic speech, and computer-based speech research.
There are two main components in this first official release. For those who would simply like speech output from whatever system they are using, including incorporating speech output in their applications, there is the gnuspeechsa tarball (currently 0.1.5), a cross-platform speech synthesis application, compiled using CMake.
For those interested in an interactive system that gives access to the underlying algorithms and databases involved, providing an understanding of the mechanisms, databases, and output forms involved, as well as a tool for experiment and new language creation, there is the gnuspeech tarball (currently 0.9) that embodies several sub-apps, including the interactive database creation system Monet (My Own Nifty Editing Tool), and TRAcT (the Tube Resonance Access Tool) — a GUI interface to the tube resonance model used in gnuspeech, that emulates the human vocal tract and provides the basis for an accurate rendition of human speech.
This second tarball includes full manuals on both Monet and TRAcT. The Monet manual covers the compilation and installation of gnuspeechsa on a Macintosh under OS X 10.10.x, and references the related free software that allows the speech to be incorporated in applications. Appendix D of the Monet manual provides some additional information about gnuspeechsa and associated software that is available, and details how to compile it using CMake on the Macintosh under 10.10.x (Yosemite).
The digitally signed tarballs may be accessed at
http://ftp.gnu.org/gnu/gnuspeech/
There is a list of mirrors at http://www.gnu.org/order/ftp.html and the site http://ftpmirror.gnu.org/gnuspeech will redirect to a nearby mirror
A longer project description and credits may be found at: http://www.gnu.org/software/gnuspeech/
which is also linked to a brief (four page) project history/component description, and a paper on the Tube Resonance Model by Leonard Manzara.
Signed: David R Hill
———————–
drh@firethorne.com
http://www.gnu.org/software/gnuspeech/
http://savannah.gnu.org/projects/gnuspeech
https://savannah.gnu.org/users/davidhill
,不過眼前恐得了解編譯安裝之法。


 pkg_dir
make
sudo make install
sudo ldconfig
# 測試
./gnuspeech_sa -c $pkg_dir/data/en -p /tmp/test_param.txt -o /tmp/test.wav "He
llo world." && aplay -q /tmp/test.wav
pkg_dir
make
sudo make install
sudo ldconfig
# 測試
./gnuspeech_sa -c $pkg_dir/data/en -p /tmp/test_param.txt -o /tmp/test.wav "He
llo world." && aplay -q /tmp/test.wav