由於 Michael Nielsen 先生此處談及之章節,淺顯易明︰
A simple network to classify handwritten digits
Having defined neural networks, let’s return to handwriting recognition. We can split the problem of recognizing handwritten digits into two sub-problems. First, we’d like a way of breaking an image containing many digits into a sequence of separate images, each containing a single digit. For example, we’d like to break the image

We’ll focus on writing a program to solve the second problem, that is, classifying individual digits. We do this because it turns out that the segmentation problem is not so difficult to solve, once you have a good way of classifying individual digits. There are many approaches to solving the segmentation problem. One approach is to trial many different ways of segmenting the image, using the individual digit classifier to score each trial segmentation. A trial segmentation gets a high score if the individual digit classifier is confident of its classification in all segments, and a low score if the classifier is having a lot of trouble in one or more segments. The idea is that if the classifier is having trouble somewhere, then it’s probably having trouble because the segmentation has been chosen incorrectly. This idea and other variations can be used to solve the segmentation problem quite well. So instead of worrying about segmentation we’ll concentrate on developing a neural network which can solve the more interesting and difficult problem, namely, recognizing individual handwritten digits.
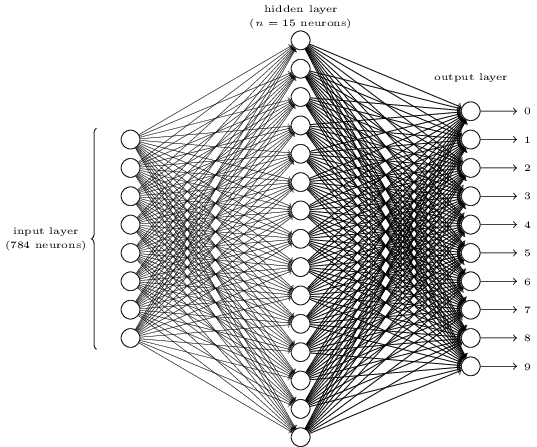
To recognize individual digits we will use a three-layer neural network:
───
於是心想何不趁此機會,介紹讀者一本理論性『神經網絡』的好書

Neural Networks – A Systematic Introduction
Raúl Rojas, Springer-Verlag, Berlin, 1996, 502 S. (two editions)
Book Description
Neural networks are a computing paradigm that is finding increasing attention among computer scientists. In this book, theoretical laws and models previously scattered in the literature are brought together into a general theory of artificial neural nets. Always with a view to biology and starting with the simplest nets, it is shown how the properties of models change when more general computing elements and net topologies are introduced. Each chapter contains examples, numerous illustrations, and a bibliography. The book is aimed at readers who seek an overview of the field or who wish to deepen their knowledge. It is suitable as a basis for university courses in neurocomputing.
希望十年前之慧劍,仍能在今日開疆闢土耶??
Neural Networks – A Systematic Introduction
a book by Raul Rojas
Foreword by Jerome Feldman
Springer-Verlag, Berlin, New-York, 1996 (502 p.,350 illustrations).

Whole Book (PDF)
切莫祇淺嚐即止乎!!
One and Two Layered Networks
6.1 Structure and geometric visualization
In the previous chapters the computational properties of isolated threshold units have been analyzed extensively. The next step is to combine these elements and look at the increased computational power of the network. In this chapter we consider feed-forward networks structured in successive layers of computing units.
6.1.1 Network architecture
The networks we want to consider must be defined in a more precise way in terms of their architecture. The atomic elements of any architecture are the computing units and their interconnections. Each computing unit collects the information from  input lines with an integration function
input lines with an integration function  . The total excitation computed in this way is then evaluated using an activation function
. The total excitation computed in this way is then evaluated using an activation function  . In perceptrons the integration function is the sum of the inputs. The activation (also called output function) compares the sum with a threshold. Later we will generalize
. In perceptrons the integration function is the sum of the inputs. The activation (also called output function) compares the sum with a threshold. Later we will generalize  to produce all values between 0 and 1. In the case of
to produce all values between 0 and 1. In the case of  some functions other than addition can also be considered [454], [259]. In this case the networks can compute some difficult functions
some functions other than addition can also be considered [454], [259]. In this case the networks can compute some difficult functions
with fewer computing units.
Definition 9. A network architecture is a tuple  consisting of a set I of input sites, a set
consisting of a set I of input sites, a set  of computing units, a set
of computing units, a set  of output sites and a set
of output sites and a set  of weighted directed edges. A directed edge is a tuple
of weighted directed edges. A directed edge is a tuple  whereby
whereby  ,
,  and
and  .
.
The input sites are just entry points for information into the network and do not perform any computation. Results are transmitted to the output sites. The set consists of all computing elements in the network. Note that the edges between all computing units are weighted, as are the edges between input and output sites and computing units.
………