何謂陣列運算呢?維基百科詞條這麼說︰
Array programming
In computer science, array programming refers to solutions which allow the application of operations to an entire set of values at once. Such solutions are commonly used in scientific and engineering settings.
Modern programming languages that support array programming (also known as vector or multidimensional languages) have been engineered specifically to generalize operations on scalars to apply transparently to vectors, matrices, and higher-dimensional arrays. These include Fortran 90, Mata, MATLAB, Analytica, TK Solver (as lists), Octave, R, Cilk Plus, Julia, Perl Data Language (PDL), Wolfram Language, and the NumPy extension to Python. In these languages, an operation that operates on entire arrays can be called a vectorized operation,[1] regardless of whether it is executed on a vector processor or not.
Array programming primitives concisely express broad ideas about data manipulation. The level of concision can be dramatic in certain cases: it is not uncommon to find array programming language one-liners that require more than a couple of pages of Java code.[2]
Concepts of array
The fundamental idea behind array programming is that operations apply at once to an entire set of values. This makes it a high-level programming model as it allows the programmer to think and operate on whole aggregates of data, without having to resort to explicit loops of individual scalar operations.
Iverson described the rationale behind array programming (actually referring to APL) as follows:[3]
most programming languages are decidedly inferior to mathematical notation and are little used as tools of thought in ways that would be considered significant by, say, an applied mathematician.
The thesis is that the advantages of executability and universality found in programming languages can be effectively combined, in a single coherent language, with the advantages offered by mathematical notation. it is important to distinguish the difficulty of describing and of learning a piece of notation from the difficulty of mastering its implications. For example, learning the rules for computing a matrix product is easy, but a mastery of its implications (such as its associativity, its distributivity over addition, and its ability to represent linear functions and geometric operations) is a different and much more difficult matter.
Indeed, the very suggestiveness of a notation may make it seem harder to learn because of the many properties it suggests for explorations.
[…] Users of computers and programming languages are often concerned primarily with the efficiency of execution of algorithms, and might, therefore, summarily dismiss many of the algorithms presented here. Such dismissal would be short-sighted since a clear statement of an algorithm can usually be used as a basis from which one may easily derive a more efficient algorithm.
The basis behind array programming and thinking is to find and exploit the properties of data where individual elements are similar or adjacent. Unlike object orientation which implicitly breaks down data to its constituent parts (or scalar quantities), array orientation looks to group data and apply a uniform handling.
Function rank is an important concept to array programming languages in general, by analogy to tensor rank in mathematics: functions that operate on data may be classified by the number of dimensions they act on. Ordinary multiplication, for example, is a scalar ranked function because it operates on zero-dimensional data (individual numbers). The cross product operation is an example of a vector rank function because it operates on vectors, not scalars. Matrix multiplication is an example of a 2-rank function, because it operates on 2-dimensional objects (matrices). Collapse operators reduce the dimensionality of an input data array by one or more dimensions. For example, summing over elements collapses the input array by 1 dimension.
不過讀來彷彿是懂非懂!舉個例講︰如果
 ,假設
,假設
![\vec{x} = [x_0, x_1, \cdots , x_{n-1}]](http://www.freesandal.org/wp-content/ql-cache/quicklatex.com-b23f5d0c458ee6a5d24120bd17bd5278_l3.png "Rendered by QuickLaTeX.com") ,那麼可得
,那麼可得
![\vec{y} = f(\vec{x}), \ where \ \vec{y} = [y_0, y_1, \cdots , y_{n-1}]](http://www.freesandal.org/wp-content/ql-cache/quicklatex.com-25427ce68aa51f7dc1013f673d6ffdfd_l3.png "Rendered by QuickLaTeX.com")
豈不好耶?☆
既簡明又清楚,不必費神多寫程式也!◎
或此正是派生『串列綜合表達式』概念之濫觴乎?!
5.1.3. List Comprehensions
List comprehensions provide a concise way to create lists. Common applications are to make new lists where each element is the result of some operations applied to each member of another sequence or iterable, or to create a subsequence of those elements that satisfy a certain condition.
For example, assume we want to create a list of squares, like:
>>> squares = [] >>> for x in range(10): ... squares.append(x**2) ... >>> squares [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
Note that this creates (or overwrites) a variable named x that still exists after the loop completes. We can calculate the list of squares without any side effects using:
squares = list(map(lambda x: x**2, range(10)))
or, equivalently:
squares = [x**2 for x in range(10)]
which is more concise and readable.
好雖是好,萬一陣列太大,計算『效能』焉能不顧呢☻
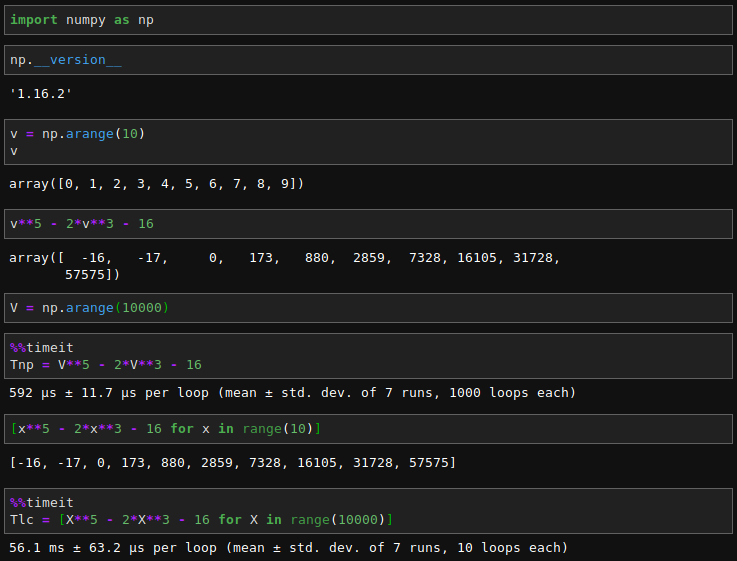








_1-1.png)




 非 ︰
非 ︰ 且︰
且︰