雖然樹莓派 3B+ 可以跑 Denny Britz 所寫的
Model-Free Prediction & Control with Temporal Difference (TD) and Q-Learning
Learning Goals
- Understand TD(0) for prediction
- Understand SARSA for on-policy control
- Understand Q-Learning for off-policy control
- Understand the benefits of TD algorithms over MC and DP approaches
- Understand how n-step methods unify MC and TD approaches
- Understand the backward and forward view of TD-Lambda
筆記本︰

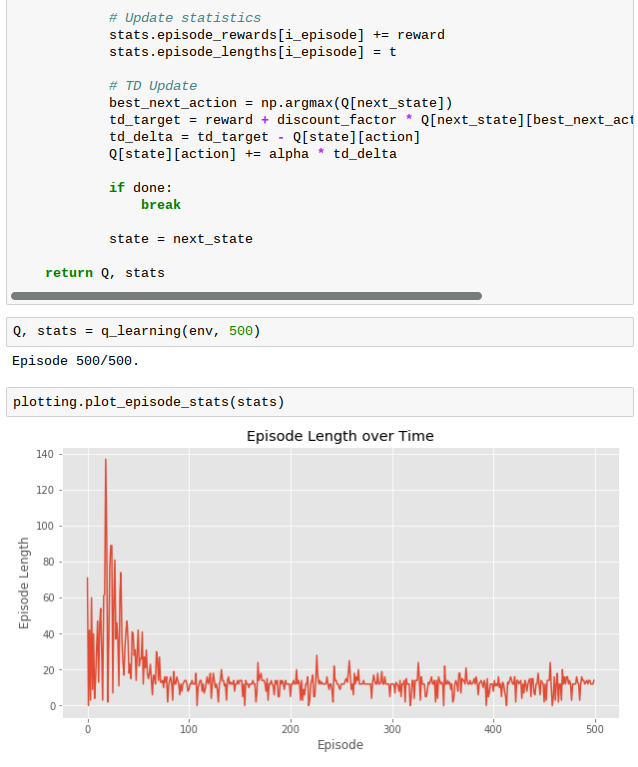
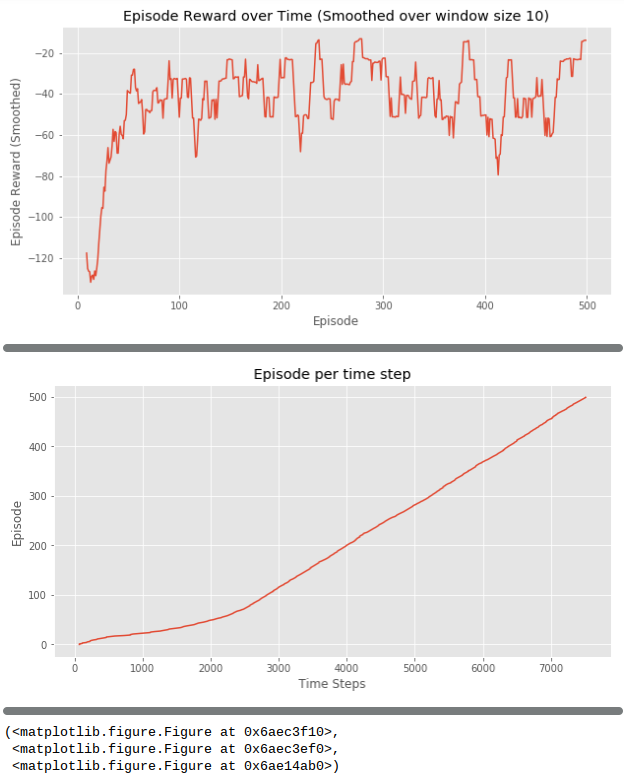
但是跑不了
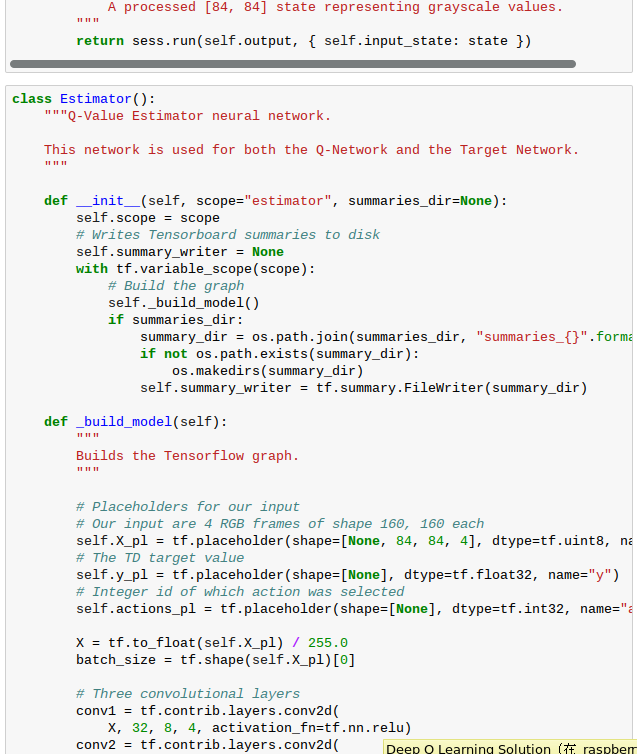
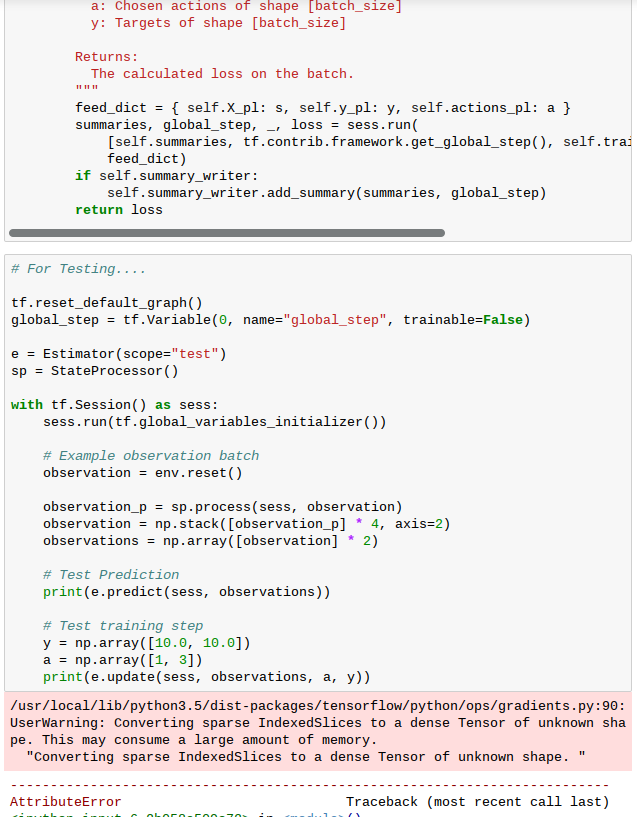
Deep Q-Learning
Learning Goals
- Understand the Deep Q-Learning (DQN) algorithm
- Understand why Experience Replay and a Target Network are necessary to make Deep Q-Learning work in practice
- (Optional) Understand Double Deep Q-Learning
- (Optional) Understand Prioritized Experience Replay
呦!

………
反思 DQN 動則需要好幾 G 記憶體,怕也太為難小樹莓了吧☺