若想了解『 gnuspeech 』是什麼?最好聽聽官網怎麼講︰
What is gnuspeech?
gnuspeech makes it easy to produce high quality computer speech output, design new language databases, and create controlled speech stimuli for psychophysical experiments. gnuspeechsa is a cross-platform module of gnuspeech that allows command line, or application-based speech output. The software has been released as two tarballs that are available in the project Downloads area of http://savannah.gnu.org/projects/gnuspeech. Those wishing to contribute to the project will find the OS X (gnuspeech) and CMAKE (gnuspeechsa) sources in the Git repository on that same page. The gnuspeech suite still lacks some of the database editing components (see the Overview diagram below) but is otherwise complete and working, allowing articulatory speech synthesis of English, with control of intonation and tempo, and the ability to view the parameter tracks and intonation contours generated. The intonation contours may be edited in various ways, as described in the Monet manual. Monet provides interactive access to the synthesis controls. TRAcT provides interactive access to the underlying tube resonance model that converts the parameters into sound by emulating the human vocal tract.
The suite of programs uses a true articulatory model of the vocal tract and incorporates models of English rhythm and intonation based on extensive research that sets a new standard for synthetic speech.
The original NeXT computer implementation is complete, and is available from the NeXT branch of the SVN repository linked above. The port to GNU/Linux under GNUStep, also in the SVN repository under the appropriate branch, provides English text-to-speech capability, but parts of the database creation tools are still in the process of being ported.
Credits for research and implementation of the gnuspeech system appear the section Thanks to those who have helped below. Some of the features of gnuspeech, with the tools that are part of the software suite, tools include:
- A Tube Resonance Model (TRM) for the human vocal tract (also known as a transmission-line analog, or a waveguide model) that truly represents the physical properties of the tract, including the energy balance between the nasal and oral cavities as well as the radiation impedance at lips and nose.
- A TRM Control Model, based on formant sensitivity analysis, that provides a simple, but accurate method of low-level articulatory control. By using the Distinctive Region Model (DRM) only eight slowly varying tube section radii need be specified. The glottal (vocal fold) waveform and various suitably “coloured” random noise signals may be injected at appropriate places to provide voicing, aspiration, frication and noise bursts.
- Databases which specify: the characteristics of the articulatory postures (which loosely correspond to phonemes); rules for combinations of postures; and information about voicing, frication and aspiration. These are the data required to produce specific spoken languages from an augmented phonetic input. Currently, only the database for the English language exists, though French vowel postures are also included.
- A text-to-augmented-phonetics conversion module (the Parser) to convert arbitrary text, preferably incorporating normal punctuation, into the form required for applying the synthesis methods.
- Models of English rhythm and intonation based on extensive researchthat are automatically applied.
- “Monet”—a database creation and editing system, with a carefully designed graphical user interface (GUI) that allows the databases containing the necessary phonetic data and dynamic rules to be set up and modified in order that the computer can “speak” arbitrary languages.
- A 70,000+ word English Pronouncing Dictionary with rules for derivatives such as plurals, and adverbs, and including 6000 given names. The dictionary also provides part-of-speech information to faciltate later addition of grammatical parsing that can further improve the excellent pronunciation, rhythm and intonation .
- Sub-dictionaries that allow different user- or application-specific pronunciations to be substituted for the default pronunciations coming from the main dictionary (not yet ported).
- Letter-to-sound rules to deal with words that are not in the dictionaries
- A parser to organise the input and deal with dates, numbers, abbreviations, etc.
- Tools for managing the dictionary and carrying out analysis of speech.
- “Synthesizer”—a GUI-based application to allow experimentation with a stand-alone TRM. All parameters, both static and dynamic, may be varied and the output can be monitored and analysed. It is an important component in the research needed to create the databases for target languages.
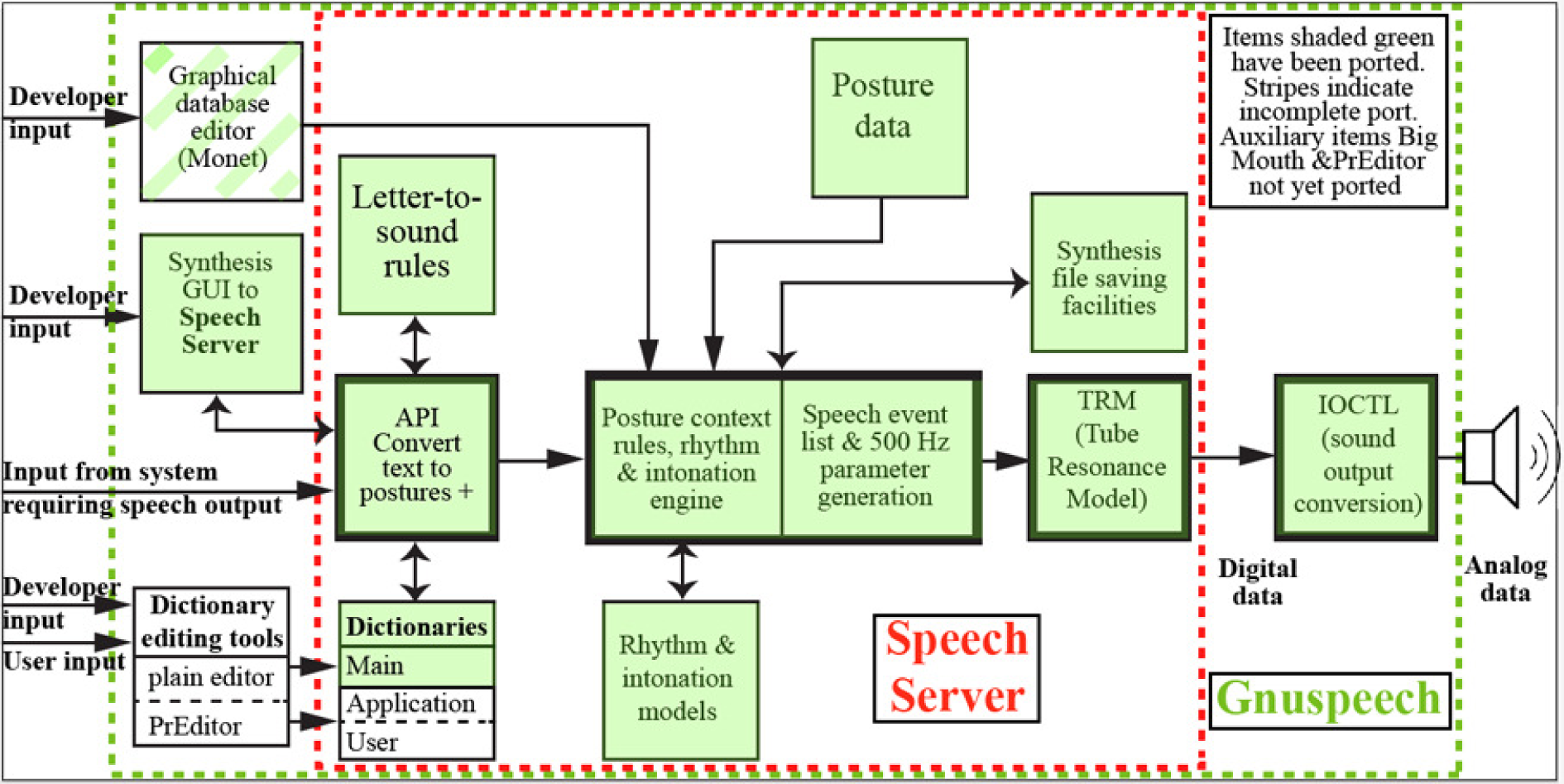
Overview of the main Articulatory Speech Synthesis System
Why is it called gnuspeech?
It is a play on words. This is a new (g-nu) “event-based” approach to speech synthesis from text, that uses an accurate articulatory model rather than a formant-based approximation. It is also a GNU project, aimed at providing high quality text-to-speech output for GNU/Linux, Mac OS X, and other platforms. In addition, it provides comprehensive tools for psychophysical and linguistic experiments as well as for creating the databases for arbitrary languages.
What is the goal of the gnuspeech project?
The goal of the project is to create the best speech synthesis software on the planet.
─── 《Gnu Speeh 編譯安裝》
從 Gnuspeech 初版發行至今已經過了兩年!雖沒有見着什麼更新?仍懷著期盼做了編譯及驗證︰
pi@raspberrypi:~![gnuspeech_sa -c /usr/local/share/gnuspeech/gnuspeechsa/data/en -p /tmp/test_param.txt -o /tmp/test.wav "Hello world." && aplay -q /tmp/test.wav Equation Diphone without formula (ignored). Equation Tetraphone without formula (ignored). Duplicate word: [articulate] Duplicate word: [associate] Duplicate word: [attribute] Duplicate word: [charro] Duplicate word: [combine] Duplicate word: [content] Duplicate word: [contrary] Duplicate word: [estimate] Duplicate word: [export] Duplicate word: [graduate] Duplicate word: [implant] Duplicate word: [imprint] Duplicate word: [incline] Duplicate word: [increase] Duplicate word: [indent] Duplicate word: [initiate] Duplicate word: [insert] Duplicate word: [insult] Duplicate word: [inter] Duplicate word: [intrigue] Duplicate word: [invite] Duplicate word: [la] Duplicate word: [mandate] Duplicate word: [moderate] Duplicate word: [object] Duplicate word: [overbid] Duplicate word: [overburden] Duplicate word: [overdose] Duplicate word: [overdose] Duplicate word: [overdress] Duplicate word: [overdress] Duplicate word: [overdrive] Duplicate word: [overhang] Duplicate word: [overhaul] Duplicate word: [overhaul] Duplicate word: [overlap] Duplicate word: [overlay] Duplicate word: [overlook] Duplicate word: [overman] Duplicate word: [overprint] Duplicate word: [override] Duplicate word: [overrun] Duplicate word: [oversize] Duplicate word: [overwork] Duplicate word: [re] pi@raspberrypi:~](http://www.freesandal.org/wp-content/ql-cache/quicklatex.com-5af264e60d2d2489efb2dc083de832e7_l3.png "Rendered by QuickLaTeX.com")
順道補之以 GitHub 網址︰
GnuspeechSA (Stand-Alone)
=========================
GnuspeechSA is a command-line articulatory synthesizer that converts text to speech.
GnuspeechSA is a port to C++/C of the TTS_Server in the original Gnuspeech (http://www.gnu.org/software/gnuspeech/) source code written for NeXTSTEP, provided by David R. Hill, Leonard Manzara, Craig Schock and contributors.
This project is based on code from Gnuspeech’s Subversion repository,
revision 672, downloaded in 2014-08-02. The source code was obtained from the directories:
nextstep/trunk/ObjectiveC/Monet.realtime
nextstep/trunk/src/SpeechObject/postMonet/server.monet
This software is part of Gnuspeech.
This software includes code from RapidXml (http://rapidxml.sourceforge.net/),
provided by Marcin Kalicinski. See the file src/rapidxml/license.txt
for details.
Status
——
Only english is supported.
License
——-
This program is free software: you can redistribute it and/or modify
it under the terms of the GNU General Public License as published by
the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the COPYING file for more details.
Usage of gnuspeech_sa
———————
gnuspeech_sa converts the input text to control parameters which will be sent to the tube model. The tube model then synthesizes the speech.
./gnuspeech_sa [-v] -c config_dir -p trm_param_file.txt -o output_file.wav \
“Hello world.”
Synthesizes text from the command line.
-v : verbose
config_dir is the directory that stores the configuration data,
e.g. data/en.
trm_param_file.txt will be generated, containing the tube model
parameters.
output_file.wav will be generated, containing the synthesized speech.
………