Notice: Trying to access array offset on value of type bool in /home1/freesand/public_html/wp-content/plugins/wiki-embed/WikiEmbed.php on line 112
Notice: Trying to access array offset on value of type bool in /home1/freesand/public_html/wp-content/plugins/wiki-embed/WikiEmbed.php on line 112
Notice: Trying to access array offset on value of type bool in /home1/freesand/public_html/wp-content/plugins/wiki-embed/WikiEmbed.php on line 116 3 月 | 2018 | FreeSandal | 第 6 頁
So you’ve classified MNIST dataset using Deep Learning libraries and want to do the same with speech recognition! Well continuous speech recognition is a bit tricky so to keep everything simple I am going to start with a simpler problem instead. Which is word recognition. I’ve seen a competition going on at Kaggle and couldn’t help but downloading the dataset.
If you think this blog post will make you an expert in Speech Recognition field please feel free to skip it. I am going to show you some quick techniques to be up and running in speech recognition area rather going deeper.
Keras was released two years ago, in March 2015. It then proceeded to grow from one user to one hundred thousand.
Hundreds of people have contributed to the Keras codebase. Many thousands have contributed to the community. Keras has enabled new startups, made researchers more productive, simplified the workflows of engineers at large companies, and opened up deep learning to thousands of people with no prior machine learning experience. And we believe this is just the beginning.
Now we are releasing Keras 2, with a new API (even easier to use!) that brings consistency with TensorFlow. This is a major step in preparation for the integration of the Keras API in core TensorFlow.
Many things have changed. This is your quick summary.
TensorFlow integration
Although Keras has supported TensorFlow as a runtime backend since December 2015, the Keras API had so far been kept separate from the TensorFlow codebase. This is changing: the Keras API will now become available directly as part of TensorFlow, starting with TensorFlow 1.2. This is a big step towards making TensorFlow accessible to its next million users.
Keras is best understood as an API specification, not as a specific codebase. In fact, going fowards there will be two separate implementations of the Keras spec: the internal TensorFlow one, available as tf.keras, written in pure TensorFlow and deeply compatible with all TensorFlow functionality, and the external multi-backend one supporting both Theano and TensorFlow (and likely even more backends in the future).
Similarly, Skymind is implementing part of the Keras spec in Scala as ScalNet, and Keras.js is implementing part of the Keras API in JavaScript, to be run in the browser. As such, the Keras API is meant to become the lingua franca of deep learning practitioners, a common language shared across many different workflows, independent of the underlying platform. A unified API convention like Keras helps with code sharing and research reproducibility, and it allows for larger support communities.
Writing code is rarely just a private affair between you and your computer. Code is not just meant for machines; it has human users. It is meant to be read by people, used by other developers, maintained and built upon. Developers who produce better code, in greater quantity, when they are kept happy and productive, working with tools they love. Developers who unfortunately are often being let down by their tools, and left cursing at obscure error messages, wondering why that stupid library doesn’t do what they thought it would. Our tools have great potential to cause us pain, especially in a field as complex as software engineering.
User experience (UX) should be central in application programming interface (API) design. A well-designed API, making complicated tasks feel easy, will probably prevent a lot more pain in this world than a brilliant new design for a bedside lamp ever would. So why does API UX design so often feel like an afterthought, compared to even furniture design? Why is there a profound lack of design culture among developers?
Part of it is simply empathic distance. While you’re writing code alone in front of your computer, future users are a distant thought, an abstract notion. It’s only when you start sitting down next to your users and watch them struggle with your API that you start to realize that UX matters. And, let’s face it, most API developers never do that.
Another problem is what I would call “smart engineer syndrome”. Programmers tend to assume that end users have sufficient background and context — because themselves do. But in fact, end users know a tiny fraction of what you know about your own API and its implementation. Besides, smart engineers tend to overcomplicate what they build, because they can easily handle complexity. If you aren’t exceptionally bright, or if you are impatient, that fact puts a hard limit on how complicated your software can be — past a certain level, you simply won’t be able to get it to work, so you’ll just quit and start over with a cleaner approach. But smart, patient people? They can just deal with the complexity, and they build increasingly ugly Frankenstein monsters, that somehow still walk. This results in the worst kind of API.
One last issue is that some developers force themselves to stick with user-hostile tools, because they perceive the extra difficulty as a badge of honor, and consider thoughtfully-designed tools to be “for the n00bs”. This is an attitude I see a lot in the more toxic parts of the deep learning community, where most things tend to be fashion-driven and superficial. But ultimately, this masochistic posturing is self-defeating. In the long run, good design wins, because it makes its adepts more productive and more impactful, thus spreading faster than user-hostile undesign. Good design is infectious.
Like most things, API design is not complicated, it just involves following a few basic rules. They all derive from a founding principle: you should care about your users. All of them. Not just the smart ones, not just the experts. Keep the user in focus at all times. Yes, including those befuddled first-time users with limited context and little patience. Every design decision should be made with the user in mind.
Here are my three rules for API design.
1 – Deliberately design end-to-end user workflows.
Most API developers focus on atomic methods rather than holistic workflows. They let users figure out end-to-end workflows through evolutionary happenstance, given the basic primitives they provided. The resulting user experience is often one long chain of hacks that route around technical constraints that were invisible at the level of individual methods.
To avoid this, start by listing the most common workflows that your API will be involved in. The use cases that most people will care about. Actually go through them yourself, and take notes. Better yet: watch a new user go through them, and identify pain points. Ruthlessly iron out those pain points. In particular:
Your workflows should closely map to domain-specific notions that users care about. If you are designing an API for cooking burgers, it should probably feature unsurprising objects such as “patty”, “cheese”, “bun”, “grill”, etc. And if you are designing a deep learning API, then your core data structures and their methods should closely map to the concepts used by people familiar with the field: models/networks, layers, activations, optimizers, losses, epochs, etc.
Ideally, no API element should deal with implementation details. You do not want the average user to deal with “primary_frame_fn”, “defaultGradeLevel”, “graph_hook”, “shardedVariableFactory”, or “hash_scope”, because these are not concepts from the underlying problem domain, they are highly specific concepts that come from your internal implementation choices.
Deliberately design the user onboarding process. How are complete newcomers going to find out the best way to solve their use case with your tool? Have an answer ready. Make sure your onboarding material closely maps to what your users care about: don’t teach newcomers how your API is implemented, teach them how they can use it to solve their own problems.
In this tutorial, we will answer some common questions about autoencoders, and we will cover code examples of the following models:
a simple autoencoder based on a fully-connected layer
a sparse autoencoder
a deep fully-connected autoencoder
a deep convolutional autoencoder
an image denoising model
a sequence-to-sequence autoencoder
a variational autoencoder
Note: all code examples have been updated to the Keras 2.0 API on March 14, 2017. You will need Keras version 2.0.0 or higher to run them.
What are autoencoders?
“Autoencoding” is a data compression algorithm where the compression and decompression functions are 1) data-specific, 2) lossy, and 3) learned automatically from examples rather than engineered by a human. Additionally, in almost all contexts where the term “autoencoder” is used, the compression and decompression functions are implemented with neural networks.
1) Autoencoders are data-specific, which means that they will only be able to compress data similar to what they have been trained on. This is different from, say, the MPEG-2 Audio Layer III (MP3) compression algorithm, which only holds assumptions about “sound” in general, but not about specific types of sounds. An autoencoder trained on pictures of faces would do a rather poor job of compressing pictures of trees, because the features it would learn would be face-specific.
2) Autoencoders are lossy, which means that the decompressed outputs will be degraded compared to the original inputs (similar to MP3 or JPEG compression). This differs from lossless arithmetic compression.
3) Autoencoders are learned automatically from data examples, which is a useful property: it means that it is easy to train specialized instances of the algorithm that will perform well on a specific type of input. It doesn’t require any new engineering, just appropriate training data.
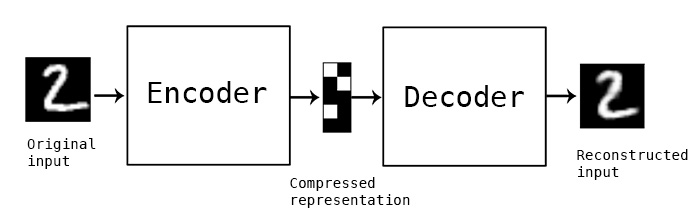
To build an autoencoder, you need three things: an encoding function, a decoding function, and a distance function between the amount of information loss between the compressed representation of your data and the decompressed representation (i.e. a “loss” function). The encoder and decoder will be chosen to be parametric functions (typically neural networks), and to be differentiable with respect to the distance function, so the parameters of the encoding/decoding functions can be optimize to minimize the reconstruction loss, using Stochastic Gradient Descent. It’s simple! And you don’t even need to understand any of these words to start using autoencoders in practice.
Keras is an open sourceneural network library written in Python. It is capable of running on top of TensorFlow, Microsoft Cognitive Toolkit, Theano, or MXNet.[1] Designed to enable fast experimentation with deep neural networks, it focuses on being user-friendly, modular, and extensible. It was developed as part of the research effort of project ONEIROS (Open-ended Neuro-Electronic Intelligent Robot Operating System),[2] and its primary author and maintainer is François Chollet, a Google engineer.
In 2017, Google’s TensorFlow team decided to support Keras in TensorFlow’s core library. Chollet explained that Keras was conceived to be an interface rather than a standalone machine-learning framework. It offers a higher-level, more intuitive set of abstractions that make it easy to develop deep learning models regardless of the computational backend used.[3]Microsoft added a CNTK backend to Keras as well, available as of CNTK v2.0.[4][5]
DataCamp’s Hugo Bowne-Anderson interviewed Keras creator and Google AI researcher François Chollet about his new book, “Deep Learning with Python”.
François Chollet is an AI & deep learning researcher, author of Keras, a leading deep learning framework for Python, and has a new book out, Deep Learning with Python. To coincide with the release of this book, I had the pleasure of interviewing François via e-mail. Feel free to reach out to us at @fchollet and @hugobowne.
In 1965, I. J. Good described for the first time the notion of “intelligence explosion”, as it relates to artificial intelligence (AI):
Let an ultraintelligent machine be defined as a machine that can far surpass all the intellectual activities of any man however clever. Since the design of machines is one of these intellectual activities, an ultraintelligent machine could design even better machines; there would then unquestionably be an “intelligence explosion,” and the intelligence of man would be left far behind. Thus the first ultraintelligent machine is the last invention that man need ever make, provided that the machine is docile enough to tell us how to keep it under control.
Decades later, the concept of an “intelligence explosion” — leading to the sudden rise of “superintelligence” and the accidental end of the human race — has taken hold in the AI community. Famous business leaders are casting it as a major risk, greater than nuclear war or climate change. Average graduate students in machine learning are endorsing it. In a 2015 email surveytargeting AI researchers, 29% of respondents answered that intelligence explosion was “likely” or “highly likely”. A further 21% considered it a serious possibility.
The basic premise is that, in the near future, a first “seed AI” will be created, with general problem-solving abilities slightly surpassing that of humans. This seed AI would start designing better AIs, initiating a recursive self-improvement loop that would immediately leave human intelligence in the dust, overtaking it by orders of magnitude in a short time. Proponents of this theory also regard intelligence as a kind of superpower, conferring its holders with almost supernatural capabilities to shape their environment — as seen in the science-fiction movie Transcendence (2014), for instance. Superintelligence would thus imply near-omnipotence, and would pose an existential threat to humanity.
This science-fiction narrative contributes to the dangerously misleading public debate that is ongoing about the risks of AI and the need for AI regulation. In this post, I argue that intelligence explosion is impossible — that the notion of intelligence explosion comes from a profound misunderstanding of both the nature of intelligence and the behavior of recursively self-augmenting systems. I attempt to base my points on concrete observations about intelligent systems and recursive systems.
This is a reply to Francois Chollet, the inventor of the Keras wrapper for the Tensorflow and Theano deep learning systems, on his essay “The impossibility of intelligence explosion.”In response to critics of his essay, Chollet tweeted:
If you post an argument online, and the only opposition you get is braindead arguments and insults, does it confirm you were right? Or is it just self-selection of those who argue online?
And he earlier tweeted:
Don’t be overly attached to your views; some of them are probably incorrect. An intellectual superpower is the ability to consider every new idea as if it might be true, rather than merely checking whether it confirms/contradicts your current views.
Chollet’s essay seemed mostly on-point and kept to the object-level arguments. I am led to hope that Chollet is perhaps somebody who believes in abiding by the rules of a debate process, a fan of what I’d consider Civilization; and if his entry into this conversation has been met only with braindead arguments and insults, he deserves a better reply. I’ve tried here to walk through some of what I’d consider the standard arguments in this debate as they bear on Chollet’s statements.
As a meta-level point, I hope everyone agrees that an invalid argument for a true conclusion is still a bad argument. To arrive at the correct belief state we want to sum all the valid support, and only the valid support. To tally up that support, we need to have a notion of judging arguments on their own terms, based on their local structure and validity, and not excusing fallacies if they support a side we agree with for other reasons.
My reply to Chollet doesn’t try to carry the entire case for the intelligence explosion as such. I am only going to discuss my take on the validity of Chollet’s particular arguments. Even if the statement “an intelligence explosion is impossible” happens to be true, we still don’t want to accept any invalid arguments in favor of that conclusion.
………
令人省思『必然遇上偶然』,可能難說乎★
教育的宗旨是
『改』正思維的『誤謬』,『變』化習性之『偏差』。
一九六三年美國 NBC 電視台初次公演了由 Jay Stewart 和 Monty Hall 主持的『Let’s Make a Deal』成交約定遊戲。它有多種版本,典型的遊戲是︰
There are countless deep learning frameworks available today. Why use Keras rather than any other? Here are some of the areas in which Keras compares favorably to existing alternatives.
Keras prioritizes developer experience
Keras is an API designed for human beings, not machines. Keras follows best practices for reducing cognitive load: it offers consistent & simple APIs, it minimizes the number of user actions required for common use cases, and it provides clear and actionable feedback upon user error.
This makes Keras easy to learn and easy to use. As a Keras user, you are more productive, allowing you to try more ideas than your competition, faster — which in turn helps you win machine learning competitions.
This ease of use does not come at the cost of reduced flexibility: because Keras integrates with lower-level deep learning languages (in particular TensorFlow), it enables you to implement anything you could have built in the base language. In particular, as tf.keras, the Keras API integrates seamlessly with your TensorFlow workflows.
Keras has broad adoption in the industry and the research community
With over 200,000 individual users as of November 2017, Keras has stronger adoption in both the industry and the research community than any other deep learning framework except TensorFlow itself (and Keras is commonly used in conjunction with TensorFlow).
You are already constantly interacting with features built with Keras — it is in use at Netflix, Uber, Yelp, Instacart, Zocdoc, Square, and many others. It is especially popular among startups that place deep learning at the core of their products.
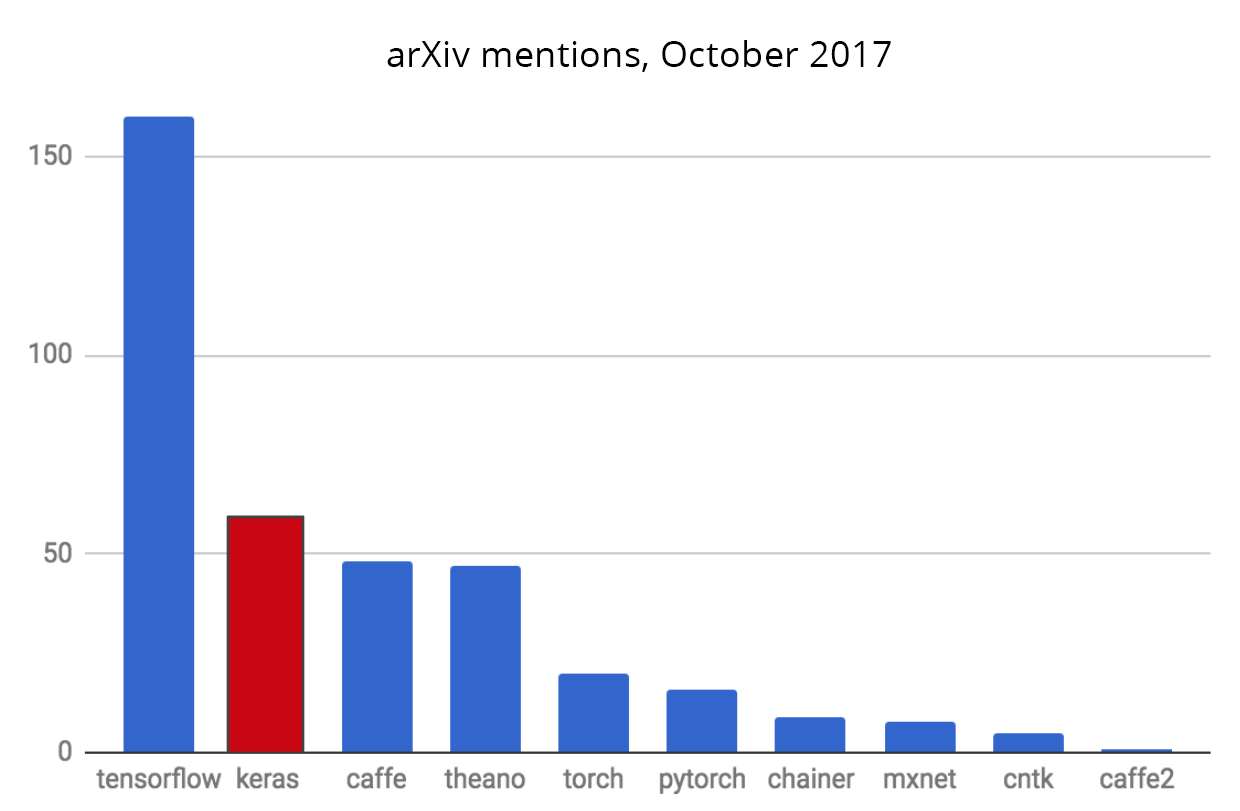
Keras is also a favorite among deep learning researchers, coming in #2 in terms of mentions in scientific papers uploaded to the preprint server arXiv.org:
Keras has also been adopted by researchers at large scientific organizations, in particular CERN and NASA.
Keras makes it easy to turn models into products
Your Keras models can be easily deployed across a greater range of platforms than any other deep learning framework:
On iOS, via Apple’s CoreML (Keras support officially provided by Apple)
On Android, via the TensorFlow Android runtime. Example: Not Hotdog app
In the browser, via GPU-accelerated JavaScript runtimes such as Keras.js and WebDNN
Keras is a high-level neural networks API, written in Python and capable of running on top of TensorFlow, CNTK, orTheano. It was developed with a focus on enabling fast experimentation. Being able to go from idea to result with the least possible delay is key to doing good research.
Use Keras if you need a deep learning library that:
Allows for easy and fast prototyping (through user friendliness, modularity, and extensibility).
Supports both convolutional networks and recurrent networks, as well as combinations of the two.
This repository contains Jupyter notebooks implementing the code samples found in the book Deep Learning with Python (Manning Publications). Note that the original text of the book features far more content than you will find in these notebooks, in particular further explanations and figures. Here we have only included the code samples themselves and immediately related surrounding comments.
These notebooks use Python 3.6 and Keras 2.0.8. They were generated on a p2.xlarge EC2 instance.








 ,所以『選中』的機會是
,所以『選中』的機會是  。然而現在主持人打開了一扇沒有『樂透獎』的門,這個『資訊』將使得未選中之『僅存之門』的機會成了
。然而現在主持人打開了一扇沒有『樂透獎』的門,這個『資訊』將使得未選中之『僅存之門』的機會成了 

 ,『二分之一者』 Halfer 認為是
,『二分之一者』 Halfer 認為是  。睡美人真的能有一個『正確答案』嗎?一個只擲一次頭尾兩種結果的硬幣,帶出可能一天或兩天的訪談,將要如何思考『機率』的先驗或後驗說法的呢?一般機率論是用『各種可能出現之狀況』 ── 樣本空間 ── 的『相對發生頻率』來作測度;如果不能測度時,或許用著『無差別』或說『無法區分』去假設它們相對發生頻率都『一樣』。這樣『樣本空間』與『測度假設』就是爭論的緣由的了。假使我們用硬幣結果集合 {頭,尾} 與訪談時間集合 {禮拜一,禮拜二},從公平硬幣角度來看這個問題中的事件機率︰
。睡美人真的能有一個『正確答案』嗎?一個只擲一次頭尾兩種結果的硬幣,帶出可能一天或兩天的訪談,將要如何思考『機率』的先驗或後驗說法的呢?一般機率論是用『各種可能出現之狀況』 ── 樣本空間 ── 的『相對發生頻率』來作測度;如果不能測度時,或許用著『無差別』或說『無法區分』去假設它們相對發生頻率都『一樣』。這樣『樣本空間』與『測度假設』就是爭論的緣由的了。假使我們用硬幣結果集合 {頭,尾} 與訪談時間集合 {禮拜一,禮拜二},從公平硬幣角度來看這個問題中的事件機率︰